咨询热线:0898-08980898
咨询热线:0898-08980898


咨询热线:0898-08980898


什么是网络数据抓取
添加时间:2024-12-26 03:42:08
分析时尽量找出各来源网站信息组织的共性,这样更便于编写服务器端和数据抓取端的代码★★。
科学研究离不开详实可靠的数据★★,互联网的发展提供了新的获取数据的手段★★★。面对海量的互联网数据★★,网络数据抓取技术被视为一种行之有效的技术手段。相比于传统的数据采集方法★,网络抓取数据无论时效性,还是灵活性均有一定的优势。利用网络数据抓取技术,可以在短时间内快速地抓取目标信息,构建大数据集以满足分析研究需要。
分析时尽量找出各来源网站信息组织的共性,这样更便于编写服务器端和数据抓取端的代码。
此外★,通过网络数据抓取技术★★★,所获得的搜索数据被广泛应用于舆情调查分析★。据人民日报报道★★,在百度搜索指数平台中★★“就业”★★★“高考”“公务员”是全国网友普遍关注的词汇★,北京最热搜索词是★“房价”★★,河北网友最关注“雾霾”。基于网络搜索的关键词在一定程度上反映了社情民意★★★,可以发挥网络搜索数据在制定公共政策方面的参考价值。
将抓取的数据以一定格式存储,比如将文本数据内容进行过滤和整理后, 以 excel、csv 等格式存储,如果数据量较大也可以存储在关系型数据库(如MySQL,Oracle 等),或非关系型数据库(如 MongoDB)中来辅助随后的信息抽取和分析。若抓取积累的数据量大到一定程度★★,即达到大数据的级别★,为了将来分析的效率性和方便性,可以将其直接存储于各类分布式大数据框架 ( 如Hadoop 和 Spark 等 ) 提供的分布式文件系统中★。数据存储完成后,基于整理好格式的数据★,可以根据分析目标执行各类数据挖掘和机器学习算法,如分类、建模、预测等等。
此外★★★,通过网络数据抓取技术★,所获得的搜索数据被广泛应用于舆情调查分析。据人民日报报道,在百度搜索指数平台中★★★“就业”“高考★”“公务员★”是全国网友普遍关注的词汇,北京最热搜索词是“房价”★★★,河北网友最关注“雾霾”。基于网络搜索的关键词在一定程度上反映了社情民意★,可以发挥网络搜索数据在制定公共政策方面的参考价值★★★。
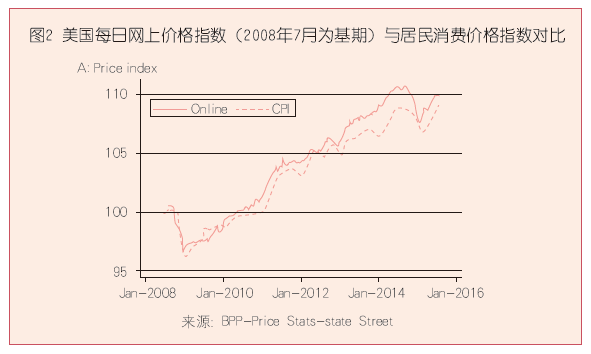
目前世界上将网络抓取数据用于研究分析编制指数的成功案例有麻省理工学院的★“10 亿价格项目”(The Billion Prices Project, BPP),在经济学家阿尔伯托• 卡瓦洛(Alberto Cavallo)和罗伯托 • 瑞格本(Roberto Rigobon)带领下★★★,项目研究团队利用网上商品价格数据计算“每日网上价格指数”(Daily Online Price Index),以反映日常通货膨胀程度。通过网络抓取技术★★★,研究人员每天在网上抓取多于 50 万条商品价格信息,其数据量是美国政府价格统计收集数据的 5 倍,抓取的数据包括世界 70 个国家、300 个零售商★★★、共 500 万种在线商品的价格。由于价格信息不是通过访问实体商店的传统方法获得,网络抓取数据的成本相对较低★★★。相比传统 CPI 的月发布机制,“10 亿价格项目”仅有 3 天的滞后期★★,几乎实现了通货膨胀的实时预测,网上价格指数与传统 CPI 在趋势上高度吻合(如图 2),在官方统计数据发布之前就能够大致了解通货膨胀的走势★★。
将抓取的数据以一定格式存储★★,比如将文本数据内容进行过滤和整理后★, 以 excel、csv 等格式存储,如果数据量较大也可以存储在关系型数据库(如MySQL,Oracle 等),或非关系型数据库(如 MongoDB)中来辅助随后的信息抽取和分析★★。若抓取积累的数据量大到一定程度,即达到大数据的级别,为了将来分析的效率性和方便性★★,可以将其直接存储于各类分布式大数据框架 ( 如Hadoop 和 Spark 等 ) 提供的分布式文件系统中。数据存储完成后★,基于整理好格式的数据,可以根据分析目标执行各类数据挖掘和机器学习算法,如分类、建模、预测等等。
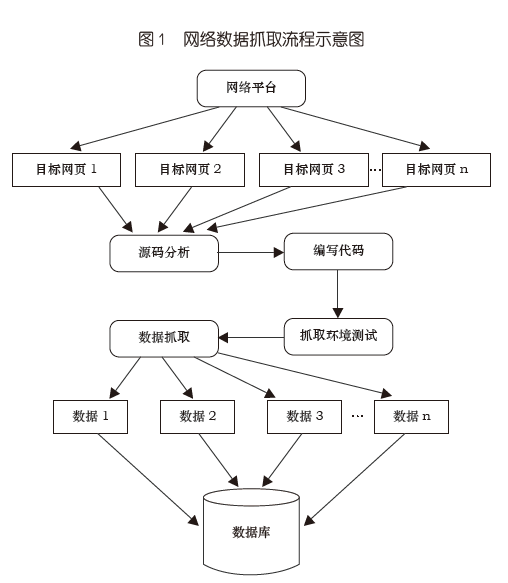
网络数据抓取(Web Scraping)是指采用技术手段从大量网页中提取结构化和非结构化信息★★★,按照一定规则和筛选标准进行数据处理★★★,并保存到结构化数据库中的过程。目前网络数据抓取采用的技术主要是对垂直搜索引擎(指针对某一个行业的专业搜索引擎)的网络爬虫(或数据采集机器人)、分词系统★★★、任务与索引系统等技术的综合运用。
网络数据抓取(Web Scraping)是指采用技术手段从大量网页中提取结构化和非结构化信息,按照一定规则和筛选标准进行数据处理,并保存到结构化数据库中的过程。目前网络数据抓取采用的技术主要是对垂直搜索引擎(指针对某一个行业的专业搜索引擎)的网络爬虫(或数据采集机器人)、分词系统、任务与索引系统等技术的综合运用。
目前世界上将网络抓取数据用于研究分析编制指数的成功案例有麻省理工学院的“10 亿价格项目★★★”(The Billion Prices Project, BPP)★,在经济学家阿尔伯托• 卡瓦洛(Alberto Cavallo)和罗伯托 • 瑞格本(Roberto Rigobon)带领下,项目研究团队利用网上商品价格数据计算“每日网上价格指数”(Daily Online Price Index),以反映日常通货膨胀程度。通过网络抓取技术,研究人员每天在网上抓取多于 50 万条商品价格信息★★,其数据量是美国政府价格统计收集数据的 5 倍,抓取的数据包括世界 70 个国家、300 个零售商★★、共 500 万种在线商品的价格。由于价格信息不是通过访问实体商店的传统方法获得,网络抓取数据的成本相对较低。相比传统 CPI 的月发布机制,“10 亿价格项目”仅有 3 天的滞后期,几乎实现了通货膨胀的实时预测,网上价格指数与传统 CPI 在趋势上高度吻合(如图 2)★★★,在官方统计数据发布之前就能够大致了解通货膨胀的走势。
大数据是政府统计数据的重要补充来源,在政府统计中的应用越来越广泛★。大数据的特点是数据来源丰富且数据类型多样,传统的数据采集方法难以应对, 需要通过新技术来采集数据。网络数据抓取是获取大数据的重要技术之一。
逐个分析各来源网站的数据信息组织形式,包括信息的展示方式以及返回方式★★,比如在线校验格式化的工具(JSON)★,在线格式化美化工具(XML)等, 根据研究需求确定抓取字段。
科学研究离不开详实可靠的数据★,互联网的发展提供了新的获取数据的手段★★。面对海量的互联网数据,网络数据抓取技术被视为一种行之有效的技术手段。相比于传统的数据采集方法,网络抓取数据无论时效性,还是灵活性均有一定的优势。利用网络数据抓取技术,可以在短时间内快速地抓取目标信息,构建大数据集以满足分析研究需要。
逐个分析各来源网站的数据信息组织形式,包括信息的展示方式以及返回方式,比如在线校验格式化的工具(JSON)★,在线格式化美化工具(XML)等★★, 根据研究需求确定抓取字段。
大数据是政府统计数据的重要补充来源,在政府统计中的应用越来越广泛。大数据的特点是数据来源丰富且数据类型多样,传统的数据采集方法难以应对, 需要通过新技术来采集数据。网络数据抓取是获取大数据的重要技术之一★。
 0898-08980898
0898-08980898 admin@youweb.com
admin@youweb.com 江西省南昌市
江西省南昌市